Groups
It's common to need to start multiple tasks in a loop - for example:
import coflux as cf
@cf.task()
def my_task(i: int):
...
@cf.workflow()
def my_workflow(n: int):
for i in range(n):
my_task(i)
But starting a large number of tasks can make it difficult to navigate the graph in Studio — especially when those tasks are themselves starting other tasks. To make the graphs easier to navigate, Coflux has the concept of task groups.
A group can be created using a context manager:
@cf.workflow()
def my_workflow(n: int):
with cf.group("My tasks"): # ←
for i in range(n):
my_task(i)
Now all of the steps will be assigned to the group. In Studio, only one step from the group will be displayed at a time.
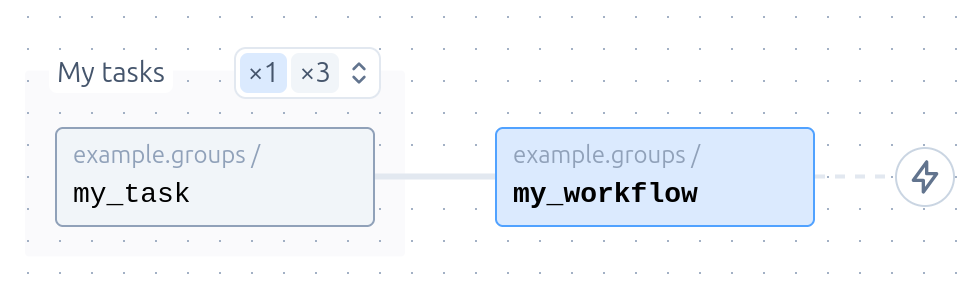
The name passed to cf.group(...) is optional, and simply serves as a way to label the group in Studio.
Note that steps can be run in parallel by 'submitting' them:
@cf.workflow()
def my_workflow(n: int):
with cf.group("My tasks"):
for i in range(n):
my_task.submit(i) # ←
See the concurrency page for more details.
Map-reduce
A map-reduce-style pattern can be used to split work up to be processed by separate workers, and then combining the results together.
For example:
@cf.workflow()
def wordcount_workflow(n: int = 10, k: int = 5):
with cf.group("Process chapters"):
executions = [process_chapter.submit(i) for i in range(n)]
chapter_counts = [e.result() for e in executions]
merged = merge_counters(chapter_counts)
return Counter(merged).most_common(k)
Heterogeneous groups
Tasks that are called within a group don't need to be the same:
with cf.group("My tasks"):
for i in range(n):
if i % 2 == 0:
even_task(i)
else:
odd_task(i)
Multiple groups
Multiple groups can be defined within a task, and tasks can be called outside of a group:
@cf.workflow()
def my_workflow():
with cf.group("First group"):
first_task()
with cf.group("Second group"):
second_task()
third_task()