Concurrency
By default, when a task is called from another task (or workflow) - e.g., with my_task() - execution will block while waiting for the called task to complete. This is more intuitive for beginners, and also makes code more portable.
Often, however, you'll want to be able to execute tasks in parallel, and collect the results later on. Or trigger a task without waiting for the result. This can be done by 'submitting' the task - e.g., with my_task.submit(...). This returns an Execution object, which is a 'future'-like object that can be used to wait for the result (using .result()), when needed:
@cf.task()
def load_user(user_id):
# ...
@cf.task()
def load_product(product_id):
# ...
@cf.workflow()
def process_order(user_id, product_id):
user_execution = load_user.submit(user_id)
product_execution = load_product.submit(product_id)
user = user_execution.result()
product = product_execution.result()
# ...
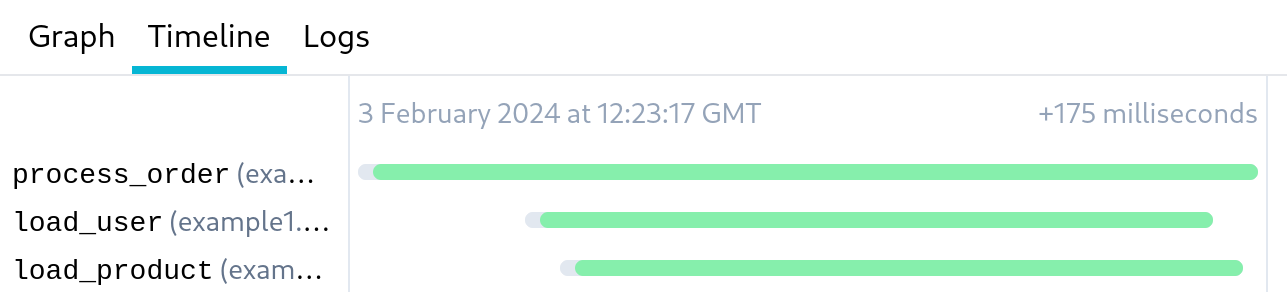
In this case, the task to load the user and the task to load the product will run in parallel, reducing the total time for the workflow to run. This is clear by looking at the timeline:
And comparing to a synchronous equivalent:
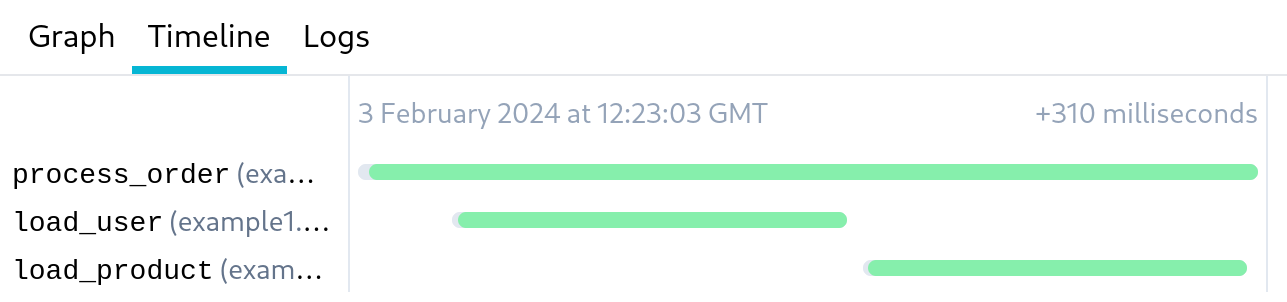
Note the longer total execution time.
Calling a task synchronously is the same as submitting it and then immediately waiting for its result. The following two workflows are equivalent:
@cf.workflow()
def my_workflow(a, b):
return my_task(a, b)
@cf.workflow()
def my_workflow(a, b):
return my_task.submit(a, b).result()
Passing and returning executions
Execution objects can be passed to other tasks as arguments, or returned from a task/workflow to avoid unnecessarily waiting for a result. They operate as a reference to the result. Demonstrating both:
@cf.workflow()
def process_order(user_id, product_id):
user_execution = load_user.submit(user_id)
product_execution = load_product.submit(product_id)
return create_order.submit(user_execution, product_execution)
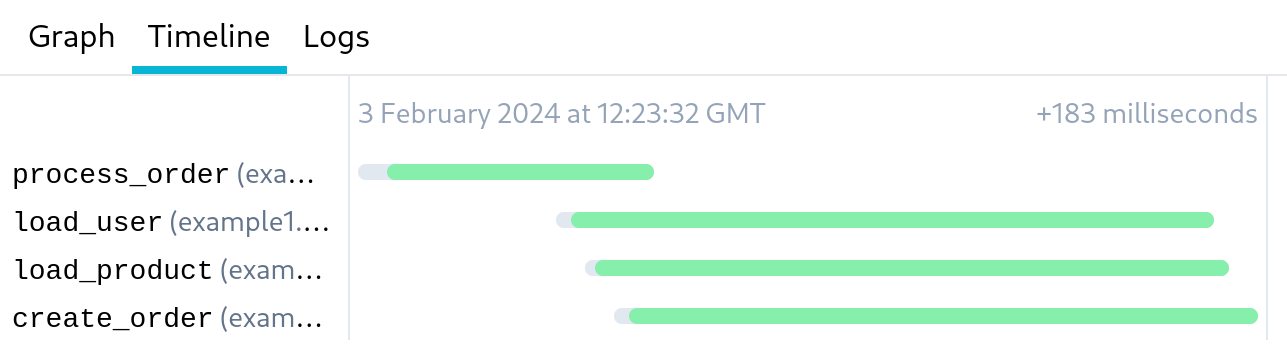
In this case, the workflow function is responsible for submitting three tasks and wiring them together, after which it can return, without waiting for the tasks themselves to complete:
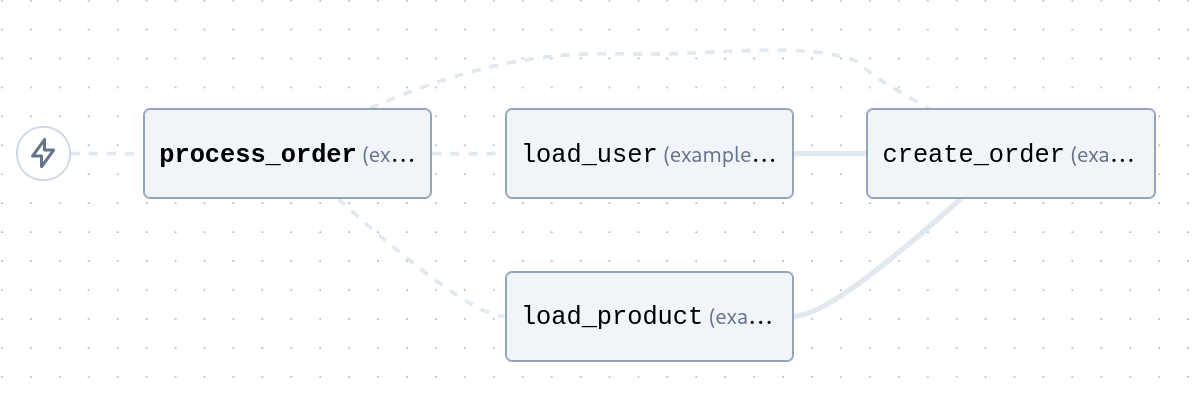
The relationships between the tasks is indicated in the graph view. The dashed line indicates that there is a parent-child relationship, but without a strict dependency. This can help to indicate the direction that data is flowing:
Explicit waiting
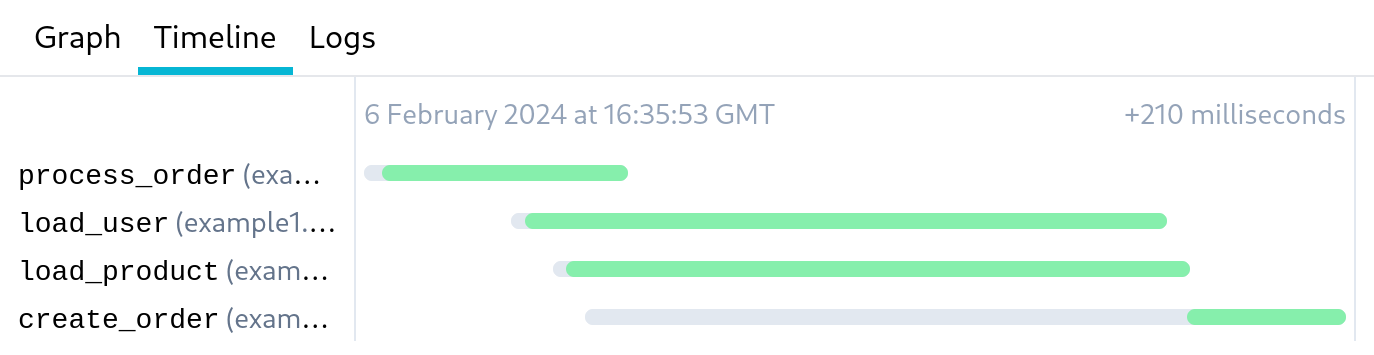
In the timeline above you can see that the create_order task is started immediately after being scheduled by the process_order. But it actually spends most of its time waiting for the results from the two 'load' tasks. We can avoid this idle time by specifying that execution of process_order shouldn't start until its dependencies are ready. To do this, we specify wait= on the @task, specifying either True, to wait for all arguments, or by specifying the names of arguments that should be waited for (either as an iterable, or a comma-separated string):
@cf.task(wait=True)
def create_order(user_execution, product_execution):
user = user_execution.result()
product = product_execution.result()
# ...
We can see from the timeline that the create_order task waits to be executed until its dependencies have completed:
If we only wanted to wait for the product, we would instead do:
@cf.task(wait={"product_execution"})
def create_order(user_execution, product_execution):
user = user_execution.result() # (this may still block waiting for the result)
product = product_execution.result() # (this result will be available)
# ...
Polling
Instead of blocking with .result(), you can use .poll() to check whether a result is ready without suspending the caller:
execution = slow_task.submit()
while (result := execution.poll(timeout=1)) is None:
print("waiting...")
poll() returns the result if it's available, or None (by default) if the execution is still running. The optional timeout parameter specifies how long to wait (in seconds) before returning None.
A custom default value can be provided with the default keyword argument:
result = execution.poll(default="not ready")
Suspense
A timeout can be imposed on the .result() call by surrounding it in a 'suspense' context. See the suspense page for details.
Fire-and-forget
A task can be submitted without ever waiting for the result. In this case the caller doesn't have a way to know that the task was successful, but it may be acceptable to rely on the retry mechanism or separate monitoring.
An example use case might be sending a notification to a user.
Cancelling executions
Once a task or workflow has been submitted, the returned Execution can be used to cancel the running execution:
@cf.workflow()
def my_workflow():
execution = another_workflow.submit()
# ...
execution.cancel()
In this case my_workflow submits another_workflow (causing a separate run to be started), but then cancels it. The effect is the same as if the run had been cancelled in Studio.